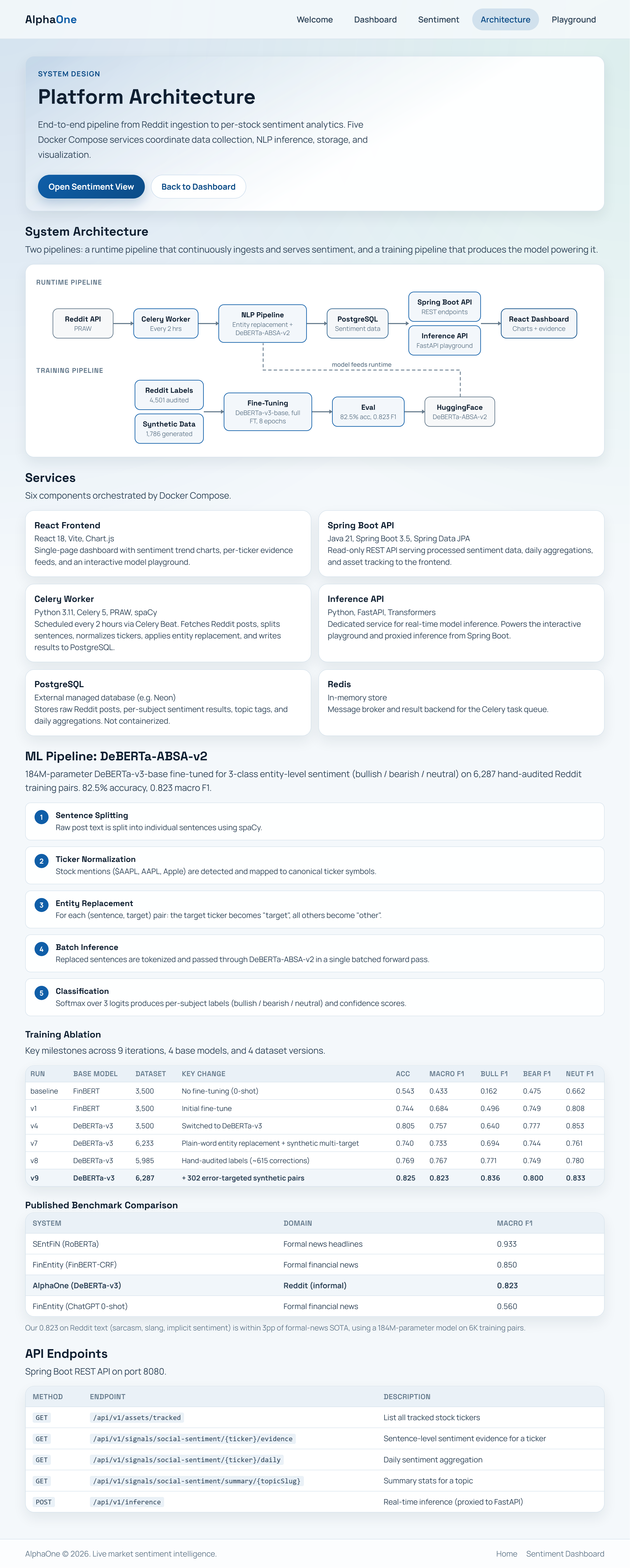
Under The Hood
Dual API Layer
Spring Boot serves processed sentiment data (daily trends, evidence feeds, macro aggregation). FastAPI handles real-time inference with attention extraction for the interactive playground.
3-Pass Batch Pipeline
Celery workers run a 3-pass pipeline: CPU normalization (sentence split, entity replacement), GPU batch inference (single forward pass), and database commit with idempotency fallback. Scheduled every 2 hours via Celery Beat.
Training DeBERTa-ABSA-v2
We built and iterated our own model across 9 versions: LLM-based labeling, 615 manual corrections, error-targeted synthetic data generation (6,200+ triples total), reaching 0.823 macro F1 on informal Reddit text.
Platform Architecture